半導体・集積回路技術の進歩に伴うプロセス微細化とチップ面積大規模化
が配線遅延の増加をもたらすため、現在のデジタルシステムの基本原理である
「同期式」、すなわち、システム全体に分配されるグローバルクロックを用いる
動作様式には高速性、信頼性、電力消費において明らかな性能限界が存在する。
1999年度半導体技術ロードマップ委員会報告書によれば、ハイエンド組み込みシ
ステム向けSOCの展開モデルで同期式システムが機能すると考えられる領域は、
1999-2000年時点ではまだチップ面積全体をカバーしているが、2005年には数mm
角以内に限定され、2011年にはわずか0.5mm角以内になると予想されている。こ
のことは、極めて近い将来、多数の機能が複合するVSLIシステム全体に対してこ
れまでのような同期式設計スタイルを適用することはほとんど不可能になること
を意味する。
これに対して、システム全体に分配されるクロックを使用せず、局所的な
事象生起の因果関係だけを駆動原理とする非同期式システムでは、性能が平均的
な信号伝播遅延のみで定まるため、計算と通信の局所性をフルに活用したアーキ
テクチャの採用によって素子の速度向上をそのまま直線的にシステムの性能向上
に反映し得る。また、その動作原理から「いかなる遅延変動に対しても正常動作
が保証される」特性を持ち、設計変更、製造パラメータのばらつき、動作環境変
動など、様々な局面で生じ得る予測不能な遅延変動の影響を受けない。そのため、
高い信頼性が得られるとともにモジュラー設計が可能となり、設計複雑度の低減
及び設計コストの大幅低減が期待できる。さらに必要な時に必要な場所でしか信
号遷移(電力消費) が起きないことから、システム電力消費を低減できる余地が
大きい。
我々は、商用RISCマイクロプロセッサMIPS-R2000と互換の 非同期式マイクロプロセッサTITAC-2を世界
に先駆けて実現し、非同期式VLSI設計スタイルの有効性を実証した。しかし、現
状では非同期式設計スタイルを支援する十分なCAD環境がないことがその普及、
実用化を妨げている。
本研究の目的は、VLSIシステムの高品質設計環境を実現するため、現行の
同期式設計と融合あるいは代替可能な非同期式VLSI設計用CADシステムを提供す
ることである。また、その要素技術である非同期式論理合成、設計検証、レイア
ウト支援技術、非同期式VLSI設計スタイルを確立することである。
半導体・集積回路技術の進歩に伴う素子の微細化とシステムの大規模化が
進むに従い、配線遅延が支配的になる。そのため、クロックをチップ全域
に位相差無く分配する同期式システムでは、期待されるスイッチング速度
の向上がシステムの性能向上に直接反映されなくなると予想されている。
一方、事象生起の因果関係に基づいて動作する非同期式システムは、クロッ
クの制約から解放されるため、計算の局所性を活かしたアーキテクチャ、
信号伝播の平均距離を最小にするレイアウト戦略の採用によって、素子の
高速性をそのまま直線的にシステムの性能向上に反映し得る。
しかしながら、非同期式システムでは、要求-応答プロトコルに伴う遅延が
性能に対するオーバーヘッドとなるため、速度性能を得ることが難しい。
従って、配線遅延を無視し得る狭小領域で、しかも遅延変動が充分小さい
場合、同期式システムの方が有利と言える。一方、入力データに依存して
処理遅延が大きく変動する場合には、狭小領域であっても非同期式システ
ムの方が有利である。また、速度性能上クリティカルパスとはならないブ
ロックでは、遅延モデルで規定された範囲内ではどのように遅延が変動し
ても正しく動作する非同期式システムの方が、論理合成や配置配線段階の
設計が容易となる可能性がある。従って、将来の複合化集積システムを構
成する機能モジュールの設計スタイルとして、事象駆動原理と局所クロッ
クを併用した同期・非同期融合型の設計スタイルが構想される。
我々は、このような同期・非同期融合型VLSIシステムの設計に適用出来る
非同期式VLSIシステムの一設計方式を提案している。提案している設計方
式では、遅延情報を利用することで、遅延変動に対してある程度のロバス
ト性を保持しつつ、速度性能の高い回路を構成することが出来る。本設計
モデルに基づく非同期式システム設計の支援を行うツールがAINOSシステム
である。AINOSシステムでは、現状の同期式システム設計支援CADとの融合
を考慮し、同期式RTLを入力仕様として利用し、それを非同期化する設計フ
ローを取っている。
非同期式システムを設計する際には、素子や配線の遅延に関して設ける仮
定が重要な役割を果たす。この仮定のことを遅延モデルと呼ぶ。従来の理
論的な非同期式システムの研究では、SIモデルやQDIモデルに基づいた回路
設計が広く行われてきた。SIモデルやQDIモデルでは、遅延の上限値は有限
であるが未知と仮定している。これらのモデルに基づいた設計では、現実
的には起こりそうもない遅延変動が生じても正しく動作するように設計さ
れるため、回路規模が大きくなり、速度性能を得ることが困難となる。そ
こで、より現実的な遅延仮定として、設計段階で遅延情報を利用すること
が出来ることを前提とし、「回路要素の絶対的な遅延変動の大きさには上
限はないが、互いに他の要素の遅延に対する相対的な遅延変動率には上限
がある」と仮定するSDI (Scalable-Delay-Insensitive)モデルに基づいて
設計する。
SDIモデルに基づいた設計では、遅延変動率の比の上限値を示すKという指
標を用いる。図1に示すように、共通遷移t からのパスにおいて、
遅いパスの遅延(d2)が速いパスの遅延(d1)のK倍以上となるように回路を
構成することで、信号遷移t2 は信号遷移t1よりも後に生じ
るとする順序付けを保証する。
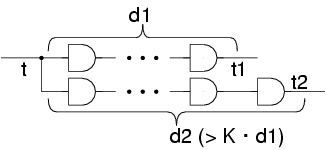
図1. SDIモデルに基づいた回路実現
非同期式システムでデータパス論理回路を実現するためには、論理動作が
いつ完了したかを検知する仕組みが必要となる。その実現手法として、2線
2相式、あるいは束データ方式がある。2線式2相式とは、1ビットの信号を
肯定、否定の2本の信号線対で表し、2線式符号(1,0),(0,1)とスペーサ
(0,0)を交互に送ることでデータ転送を繰り返す方式である。束データ方式
はデータ信号線に対して、そのデータが有効になったことを示す1ビットの
ストローブ信号を付加する方式である。ストローブ信号は遅延素子を用い
て生成され、その大きさはデータ処理遅延の最悪値に基づいたものとなる
ため、束データ方式では回路単体の速度性能は最悪遅延により制限される。
一方、加減算・論理演算などの基本的な演算では、平均遅延と最悪遅延の
差がほとんどない高速な回路構成が提案されている。また、浮動小数点演
算回路など、基本演算を組み合わせることで実現される回路では、入力デー
タに依存した個々の演算回路内での遅延変動よりも、入力データに依存し
て通過する演算回路が異なることによる遅延変動の方が大きい。従って、
個々の演算回路の速度性能は最悪遅延で制約されたとしても、それらを組
み合わせた回路で入力データに依存したパスの違いを積極的に利用するこ
とで、システム全体の速度性能を平均遅延に依存したものとすることが出
来る。提案する設計方式では、設計時に遅延情報を利用できることを前提
として、束データ方式あるいは2線2相式に基づくデータ転送を行う。
2線2相式、あるいは束データ方式に基づいたデータ転送において、要求-応
答プロトコルを図2に示すような4相ハンドシェイクとして実現すると、次
の演算を実行するための初期化の遅延がオーバーヘッドとなり、速度性能
を得ることが困難となる。
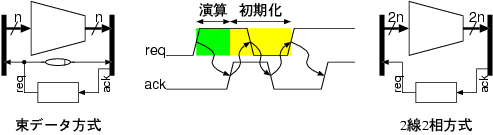
図2. 4相ハンドシェイクによるデータ転送
しかしながら、このオーバーヘッドは細粒度パイプライン化技術を用いる
ことにより、ある程度隠蔽することが出来る。細粒度化とは、「組み合わ
せ回路内にラッチを挿入して演算ステージを複数のサブステージに分割し、
後続のサブステージで演算処理を行っている間に次のデータを処理するた
めの初期化処理を行わせることにより、サイクルタイムに占める制御遅延
を隠蔽する手法」のことである。提案する設計方式では、要求-応答プロト
コルに伴う制御オーバーヘッドを隠蔽するため、細粒度化を行う。
図3 に細粒度化前と3分割に細粒度化した後の回路モデルと動作を示す。細
粒度化前は演算終了後の初期化の遅延(Init)がサイクルタイムにオーバー
ヘッドとして見えているのに対し、細粒度化することにより、後続のサブ
ステージの演算処理(1/3Te+Tw)と初期化処理(Init)が並行して行
われることでサイクルタイムに占める初期化のオーバーヘッドを隠蔽する
ことが出来る。
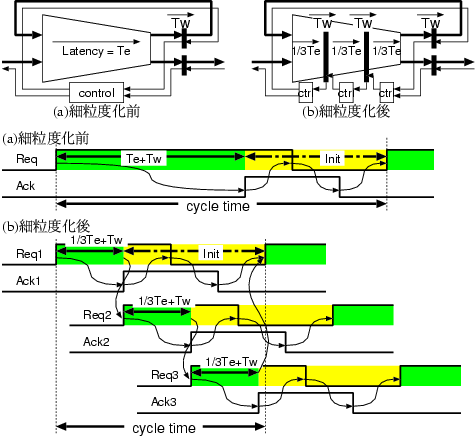
図3. 細粒度化前と細粒度化後の回路モデルと動作
細粒度化の特徴は以下の通りである。ラッチ書き込み遅延を Tw と
し、演算遅延を Te とした場合、
- n 分割の細粒度化により、(n-1)個のラッチが
挿入されるため、レイテンシが (n-1)Tw 増加する。
但し、2線式回路においてDDL(Differential Domino Logic)回路を
用いた場合、演算遅延=ラッチ書き込み遅延と見做すことが
出来るため、細粒度化によるレイテンシの増加はない。
- 図3に示すループ構造を持った回路の場合、
n 分割の細粒度化により隠蔽できるオーバーヘッドは、
最大で (n-1)/n・Te である。
従来の非同期式システム設計方式では、主に制御回路の構成に焦点が当て
られてきた。データパスと制御回路は異なる合成手法・設計手法が適用さ
れることが多く、プロセッサなどの大規模な非同期式システムを構成する
場合、はじめにデータパスと制御回路を分離することが求められてきた。
一方、同期式システムの設計では、制御回路とデータパスはいずれも只の
組み合わせ回路として論理合成出来る。この場合、データパスと制御回路
の分類は合成された回路の機能によって、便宜的に行われるに過ぎない。
同期式システムと非同期式システムの本質的な違いはタイミング信号の取
り方(生成方式)のみと考えることが出来る。そこで、制御論理とデータパ
ス論理を分離することなく、タイミング生成機構のみを要求-応答プロト
コルに基づく非同期式として実現する方式を提案する。本設計方式では、
グローバルクロックにより制御されたRTL記述を入力とし、グローバルク
ロックの代わりとなるローカルなタイミング信号を要求-応答プロトコル
に基づく非同期式として実現する。
本設計法は、図4の様に示される複数の機能モジュールの結合から成るシス
テムを対象とする。図4において、台形は組み合わせ回路を、縦棒はレジ
スタを表しており、破線で囲まれたものを一つの機能モジュールとして考
える。
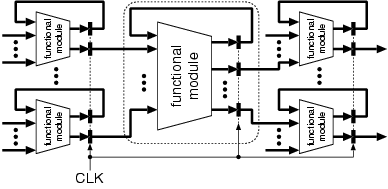
図4. 設計対象モデル