この研究は,豊橋技術科学大学の中島 浩 教授が研究代表者として遂行している 科学技術振興事業団・
戦略的想像研究推進事業 (CRESTタイプ) 「低電力化とモデリング技術によるメガスケールコンピューティング」 の一貫として行っているものである。これは Pflops
クラスの超高性能計算のための百万プロセッサ級のシステム実現のための諸技術を,コモディティ技術をベースとして Feasibility,
Dependability, Programmability の3つのポイントを重視しつつ開発することを目的としている。
本プロジェクトは 豊橋技術科学大学 情報工学系, 筑波大学 電子・情報工学系/ 計算物理学研究センター,および 東京工業大学 情報理工学研究科 数理・計算科学専攻/ 学術国際情報センター と共同して実施しており,以下のサブテーマを分担している。
本研究室では高性能かつ、高密度実装可能な低消費電力を実現するプロセッサ技術について,SCIMAアーキテクチャを提案し研究を行っている。
近年のプロセッサは、クロック周波数の向上、命令レベル並列性の活用などにより高性能化が図られているが、一方で主記憶の性能はプロセッサほど改善されていない。図1は、CPUとDRAMについて、1980年のそれぞれの性能を1とした場合の相対性能を1980年から2000年までプロットしたものである。図1からもわかるように、プロセッサとメモリの性能差は拡大しており、今後この差はさらに拡大すると予測されている。
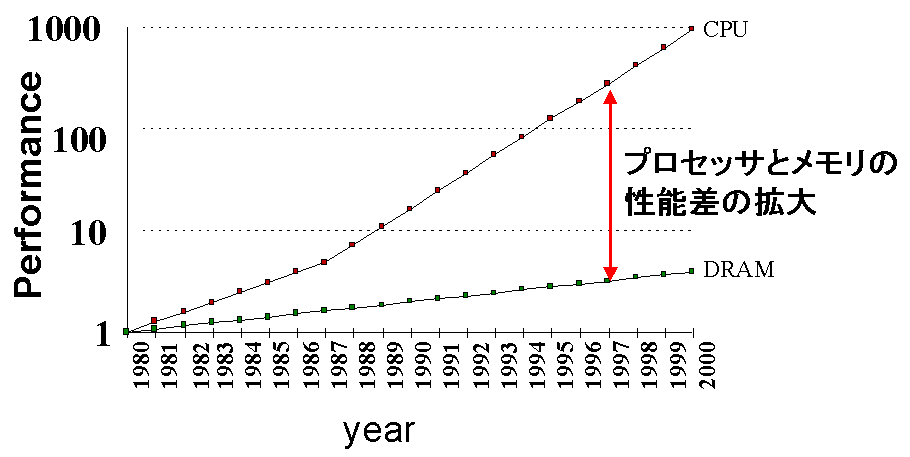
図1:
プロセッサとメモリの性能
このような状況のもと、近年のプロセッサの性能はメモリの性能により制限されてしまっている。特に、大規模科学技術計算に代表されるハイパフォーマンスコンピューティング(HPC)においては、下位のメモリ階層へのアクセス(オフチップメモリアクセス)の頻発により性能が大きく低下する。
この問題に対処するために、従来からキャッシュメモリが用いられてきた。しかし、データセットの大きなHPC分野のアプリケーションでは、キャッシュが有効に機能しないことが多い。キャッシュ容量に比べデータセットが非常に大きく、またデータの時間的局所性がほとんどないため、キャッシュミスによる主記憶へのアクセスが頻発し、性能が大きく低下する。
今後の半導体実装技術を考えると、オンチップ記憶のスループットとオフチップ記憶のスループットの性能格差はさらに広がると考えられるため、集積度の向上を頼りにプロセッサチップ上の記憶を増やし、オフチップへのアクセスを低減することが必須である。キャッシュブロッキングは、ソフトウェア的な手法でデータの再利用性を向上させることで、データへのアクセスをキャッシュという上位階層の記憶に閉じるさせる手法であり、プロセッサチップ上に実装可能なキャッシュ容量がこれからも増大するという技術動向を考えると今後も有望な手法である。
しかし、従来のキャッシュでは、データのアロケーションとリプレースメントがハードウェアで制御されるため、どのデータをキャッシュに載せるか指定できない、ラインコンフリクトによる同一配列のブロック内データの干渉や異なる配列間のデータの干渉を防げない、等の問題がある。
これらの問題は、データのアロケーションやリプレースメントがハードウェアによって暗黙的に制御されるキャッシュをソフトウェアから制御しようとするために生じる。定型的なアクセスが多い大規模科学技術計算では、データのアロケーションをハードウェアではなくむしろプログラムによりソフトウェア的に制御することが可能で、その方が性能面で有利と考えられる。そこで、チップ上に実装するメモリとして、従来のキャッシュに加えて、アドレス指定可能な主記憶の一部をSRAMとして載せる新しいアーキテクチャ、SCIMA (Software Controlled Integrated Memory Architecture)を提案している。
図2にSCIMAの構成図を示す。
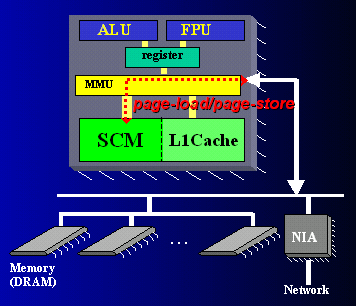
図2:
SCIMAの構成図
図2にあるように、SCIMAではプロセッサ上にキャッシュだけでなく、アドレス指定可能なSoftware Controlled Memory(SCM)を搭載する。従来のキャッシュではデータのアロケーションやリプレースメントは、ハードウェアにより暗黙的に制御されるのに対し、Software Controlled Memoryではそれらの制御をソフトウェアで明示的に行える。これがキャッシュとSoftware Controlled Memoryの本質的な違いである。Software Controlled Memoryに加えキャッシュも搭載しているのは、必ずしもすべてのデータアクセスをソフトウェアが解析できない場合を考慮しているためであり、その場合はキャッシュを用いる。
キャッシュとSoftware Controlled Memoryに割り振られる容量は、n-way連想キャッシュのうち幾つのwayをSoftware Controlled Memoryに割り当てるかによって決定される。アプリケーションの性質に応じて、wayの割り当てを実行時に再構成することにより、最適なパフォーマンスを得ることを目指す。
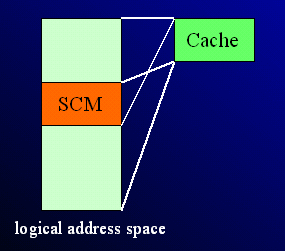
図3:
SCIMAのアドレス空間
SCIMA では論理アドレス空間上にSoftware Controlled Memory領域をマッピングする(図3)。Software Controlled Memory領域は大きな連続ブロック領域であるため、この管理をTLBではなく専用レジスタで行い、TLB ミスの頻発を防ぐ。導入するレジスタは、Software Controlled Memory領域の先頭アドレスを保持するASR (On-Chip Address Start Register) とSoftware Controlled Memoryの容量を表すAMR (On-Chip Address Mask Register) である。
拡張命令
オンチップメモリへのデータ転送を制御するため、page-load/page-store と呼ぶ主記憶・Software Controlled Memory間のデータ転送命令を追加する。本命令によるデータ転送はpageという大きな粒度で行なわれる。この命令にはブロックストライド転送の機能を付け加える。この機能によりオフチップメモリ上の不連続領域のデータをパッキングしてオンチップメモリに持ってくることが可能となり、必要なデータのみを大粒度で転送することが可能となる。 Software Controlled Memoryとレジスタ間のデータ転送は従来のload/storeを用いる。
SCIMAの利点:Performance
SCIMAにおけるデータ転送のソフトウェア制御によって以下の利点が生まれる。 これらの利点により高性能を得ることができると考えられる。
- 同一配列、あるいは異なる配列間の干渉によるコンフリクトの解消
- 再利用性のないデータがオンチップ記憶に載ることの非効率性の解消
- 大粒度転送によるオフチップメモリレーテンシの隠蔽
SCIMAの利点:Power
またSCIMAでは性能面だけではなく、以下の利点により電力消費の削減も可能である。
- オフチップトラフィック削減によるバス消費電力の低減 : データコンフリクトの解消・効率的なデータ転送によりオフチップトラフィックの削減が期待できる。
- 選択的wayアクセスによるSCMアクセスの低消費電力化 : Software Controlled Memoryへのアクセスの際は、アクセスすべきwayがアドレスから一意に決定される。これにより1つのwayのみを選択的にアクセスすることができるため、消費電力の削減につながる。
SCIMAの性能を評価するため、いくつかのベンチマークプログラムを用い、クロックレベルシミュレーションによる性能評価を行っている。その例として、Nas Parallel Benchmarks(NASPB)の中からCG・FTと、
筑波大学計算物理学研究センターで行われているQCD (量子色力学)計算の性能評価結果を図3に示す。評価パラメータは以下の通り。
- 同時発行命令数
- 整数演算: 2
- 浮動小数点演算(積和): 1
- load/store: 1
- 合計チップ内メモリサイズ: 64KB
- キャッシュ評価用: 64KB キャッシュ (4 way), 0KB Software Controlled Memory
- SCIMA評価用: 16KB キャッシュ (1 way), 48KB Software Controlled Memory
- load/storeレーテンシ: 2cycle
- オフチップメモリスループット: 4B/cycle
- オフチップメモリレーテンシ: 40cycle
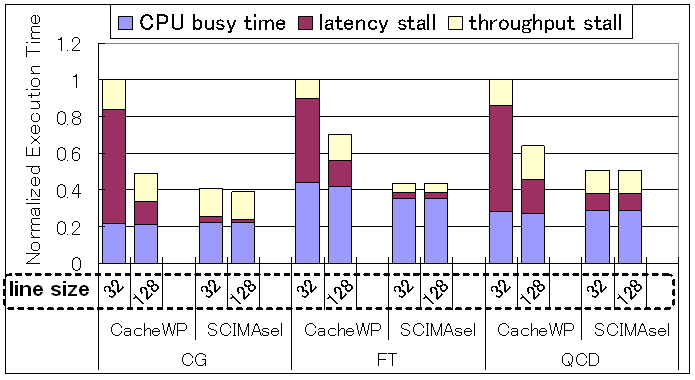
図4:
CG・FT・QCDによる性能評価
各ベンチマークの左側はMRUアルゴリズム*)によるウェイ予測を行うキャッシュアーキテクチャの性能を、右側はSCIMAの性能を示している。また、各々キャッシュラインが32KBと128KBの2通りについて示している。図よりSCIMAはキャッシュラインサイズが32KBのときに平均2.2倍、128KBのときで平均1.4倍、キャッシュ型アーキテクチャに比べ高速であることがわかる。この結果より、SCIMAでは従来のキャッシュベースのアーキテクチャに比べ高い性能が達成できると言える。
*) K. Inoue el al., “Way-Predicting Set-Associative Cache for High Performance and Low Energy Consumption”, ISLPED’99