情報処理1998年3月号特別論説・「情報処理最前線」
非同期式マイクロプロセッサの動向
A Perspective on Asynchronous Microprocessor
南谷 崇 (Takashi Nanya)
東京大学 先端科学技術研究センター
(Research Center for Advanced Science and Technology, The University of Tokyo)
1 はじめに
今日までの情報処理技術の発展を支えてきたコンピュータ性能の飛躍的
向上はVLSI技術の進歩に負うところが大きい。今後も、素子の微細化と
チップの高集積化が一層進むと予測されている。
しかし、コンピュータの誕生以来これまでずっと行われてきた「同期式」
システム設計ではもはや今後のVLSI技術の進歩の恩恵を十分受けられず、
プロセッサ性能が飽和点に近づきつつあることがはっきりしてきた。
このため、この数年、これを解決する新しい設計アプローチとして
「非同期式」システム設計の研究が急速に立ち上がり、
非同期式マイクロプロセッサの研究開発もいくつか進行している。
本稿では、現在の同期式設計が直面する問題点、
非同期式設計の基本原理、
非同期式マイクロプロセッサの開発事例を紹介し、
その実用化への課題と将来の可能性を展望する。
2 同期式プロセッサの性能限界
マイクロプロセッサに代表されるディジタルシステムあるいは
ディジタル電子機器がクロックと呼ぶ特別な方形波信号に同期して
その動作を進める、というのは常識である。
システムの動作解析、論理設計はすべて、
クロック信号で定められる周期的タイミングを基にして行われる。
アーキテクチャが同じならばプロセッサ速度はクロック周波数で決まる。
クロック周波数は、
プロセッサ内の任意の二つのレジスタ間のデータ転送に要する時間の
最大値で決まる。
従って、プロセッサを速くしたければ、
レジスタ間データ転送時間の最大値が
できるだけ小さくなるように論理設計を行い、
クロック周波数を上げればよい。
実際、これまで、半導体製造技術の世代交替が起きるたびに、
ゲート遅延の減少にほぼ見合ってクロック周波数が上がってきた。
そうしてプロセッサの性能向上と大規模化が達成されてきた。
ところが、最近、様子が違ってきた。
半導体集積回路構造の微細化が進むと、ゲート遅延は減少する。
その一方、微細化で配線抵抗は増えるために
同じ長さでも配線遅延は絶対的に増大し、
また、小さくなるゲート遅延に対して相対的にも増大する。
さらに、チップ面積も大きくなり、
搭載されるシステム規模が大きく複雑なってきたため、
配線長自体も長くなる傾向にある。
このため、VLSI設計に際して配線遅延が無視できなくなってきたのだ。
いやそれどころか、むしろ配線遅延のほうが支配的要因になりつつある。
図1に示すように、現在のVLSIプロセス技術(0.25um)でゲート遅延と
長さ43umの(アルミ)配線遅延とはほぼ同程度である[1]。
これからさらに微細化が進むにつれて、
急激に配線遅延がチップ性能の支配要因になっていく。
この傾向はアルミ配線が銅配線に置き換えられると若干緩和されるが、
配線遅延が支配的になることに変わりはない。
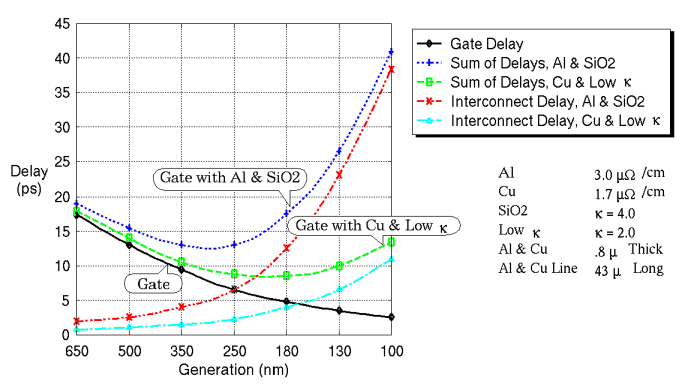
図1:技術世代推移に対するゲート遅延と配線遅延
(National Technology Roadmap for Semiconductors [SEMATECH]より)
配線遅延問題で真っ先に影響を受けるのがクロック配線である。
LSIの微細化によってせっかく論理ゲートの速度が向上しても、
その速度に見合った周波数でクロックを
チップ全体に分配することができなくなるのだ。
このため、すでに現在チップ性能は限界に近づきつつあり、
クロック分配などのタイミング制御に多大の設計コスト、
電力コストがかかるようになっている。
米国半導体産業協会(SIA) の予測[1]によれば、
西暦2012年のシリコン技術による
最先端マイクロプロセッサのオンチップ・クロック周波数は
3GHzから10GHzに達するという。
しかし、現在の同期式チップアーキテクチャでこれを達成するのは
明らかに無理だ。
真空中の電磁波信号でもチップ寸法と同程度の3cmを進むのに
0.1nsを要するからだ。
他の媒体ならもっと時間がかかることは言うまでもない。
要するに、今後のデバイス技術の進歩の果実を享受してシステム性能を
向上させようとするなら、
チップ全域に分配するクロック信号はもはや使えないのだ。
3 初めは非同期式だった!
クロック分配に起因する同期式システムの性能限界を突破する解のひと
つは、「クロックを使わない」ことである。すなわち、非同期式設計スタイル
を採用することである。クロックを使わなければ、局所計算の並列化と分散制
御によって配線遅延の影響を最小化できる。ゲート遅延減少の効果を最大限に
享受するアーキテクチャや回路構成の採用が可能になる。その結果、今後なお
予想される微細化プロセス技術の進歩の恩恵をシステム側が十分に受けること
ができる。
非同期式設計は新しい技術ではない。歴史的には、ディジタル装置は初
めは非同期式で作られていた。電話交換の制御装置を電磁リレーで作っていた
頃はクロックの概念はなかったはずだ。第2次大戦末期、米国ベル研やIBMな
どで兵器研究のため電磁リレー式自動計算装置を開発していた頃、今のクロッ
クのようなタイミング方式が生まれたらしい。電子式になってからも1940年代
には真空管を用いた非同期式演算装置あるいは計算機がいくつか試作されたよ
うだ。しかし、コンピュータがいわゆる第2世代(トランジスタ時代)に移っ
てからは、周知の通り、今日までほとんどすべてのコンピュータは共通クロッ
ク信号を用いる同期式で設計されている。特に、1970年代以降のLSI時代になっ
てからは、あらゆるディジタルシステムは同期式設計を基本とするようになっ
た。
つまり、初めにまず非同期式回路があり、1940年代の半ばに誰かがクロッ
クを発明して同期式回路が生まれたのだ。従って、同期式が生まれる前の設計
技術に対して「非」を付けて非同期式と呼ぶのは本来はおかしい。信号遷移の
因果関係に従って動作するのだから、例えば、因果式と呼ぶのがふさわしい。
トランジスタの出現で素子特性が均一になったのでクロックを用いる非因果式
が今日まで続いてきたが、VLSI技術の進歩で再び因果式による設計が必要になっ
てきたと考えれば分かりやすい。まさに「因果は巡る」ということである。し
かし、ここでは今までどおり、クロックのない回路を非同期式と呼ぶことにし
よう。さて、非同期式設計スタイルを採用することによる利点をまとめると、
次のようになる。
- 高速性:同期式システムの性能がレジスタ間データ転送の最悪ケース遅延で決ま るのに対して、非同期式システムでは局所計算の平均遅延だけで決まる。従って、信 号伝播の平均距離を最小化するチップアーキテクチャの採用によって今後の素子速度 向上の効果をそのまま享受した高速計算を実現できる。
- 信頼性:信号遷移の因果律に基づいて素子なりに動作を進めるため、予測不能な 環境変化(電源電圧、温度など)やパラメータ変化に起因する遅延変動の影響を受け ない高信頼性システムが実現できる。
- 低消費電力:現在の主流であるCMOSゲートの電力消費は、近似的には、回路中の 信号遷移の量、すなわち、単位時間当たりに充電/放電の起きる配線数、に比例する 。同期式システムでは、システム全域へのクロック分配による電力消費が大きな割合を占めるのに対して、非同期式システムではクロックがなく、与えられた計算の実行に必要な時に必要な場所でしか信号遷移は起きない。動作が要求されない部分回路の 電力消費はごくわずかな漏れ電流によるものだけである。従って、性能を犠牲にする ことなく電力消費を低減できる。
- 設計容易性:異なる二つのモジュール間のインタフェースでは要求/応答のプロ トコルに従う以外には同期式で要求されるようなタイミング調整の必要がない。そのため大規模システム設計の複雑さをモジュラー設計によって克服できる。
4 非同期式システムの動作原理
ディジタルシステムを構成する素子や配線の遅延は様々な要因で変動す
る。論理設計手法、チップレイアウト、プロセス技術、実装技術など、設計製
造段階での変動要因に加えて、電源電圧、環境温度など、稼働する環境によっ
て大きく変動する。さらに処理されるデータにも依存する。従って、システム
の生涯を通じて実際に起こり得る遅延変動の様子を推定し、その振るまいを表
す適切な遅延モデル(遅延仮定)に基づいて設計を進めることになる。
もし、現行の同期式システムのように、設計時に推定した最大遅延はシ
ステムの生涯を通じて不変であると楽観的に仮定して設計を行うと、回路構成
の効率は良くなるが、上記の要因で遅延変動が起きた場合にはクロックのタイ
ミングがずれて誤った動作を引き起こしやすい。すなわち、信頼性は低下する。
一方、素子遅延や配線遅延は互いにばらばらで自由に変動し得ると悲観的に仮
定して設計すると、遅延変動に対する信頼性は完全に保証するが、ある意味で
ムダが生じ、回路量が増えたり性能低下が生じる。
>
従って、設計の前提となる遅延モデルは素子技術、システム実装技術、
動作環境に対して十分なレベルの性能とタイミング信頼性を達成するものでな
ければならない[2], [3]。
同期式と非同期式の違いは、2値信号をレジスタ、メモリなどの記憶素
子に書き込む際に共通クロックを用いるかどうか、という点にある。ディジタ
ルシステムの基本動作はレジスタ間データ転送である。同期式では、クロック
パルスがデータを書込むタイミングを定めている。このため、クロックパルス
の到着する前に有効なデータが転送先レジスタの入力端子へ到着していなけれ
ばならない。システム全体の動作も共通クロックに合わせた周期で進む。
これに対して非同期式では、データ転送が必要(かつ可能)になったら
転送元レジスタへ要求信号を出す。その結果、転送元レジスタから送出された
データは変換回路を経て転送先レジスタへ書き込まれ、その完了を示す応答信
号が生成される。この応答信号が次のデータ転送を要求するトリガーになる。
クロックなしで、Nビット幅のデータを転送先レジスタへ書き込むタイ
ミングをどう決めるか?これは非同期式論理設計における重要な選択の一つで
ある。一般にデータ・パスの遅延は、実行される命令、データによって、また
ビット毎にも、ばらつきがある。そこでおおまかに次の二つの極端な場合に分
ける。
- 遅延のばらつきが非常に大きい場合:
1ビットデータを2本の信号線で表す2線式データ表現を用いる。従って、デー
タ幅は2Nになる。ビット毎に初期状態を(0,0)として、有効なデータの到着
(書き込みタイミング)を次のような遷移で表現する。
| (0,0) → (0,1) | "0"が到着 |
| (0,0) → (1,0) | "1"が到着 |
| (0,1), (1,0) → (0,0) | 初期状態へ復帰 |
データパス上のどのインターフェースでも、データ転送を実行するために初
期状態(0 ,0)から有効データ(0,1)または(1,0)へ遷移する期間(稼働相と呼ぶ)
と次のデータ転送に備えるために初期状態へ復帰する期間(休止相と呼ぶ)を
交互に繰り返す。これを2線2相式と呼ぶ。
- 遅延のばらつきが非常に小さい場合:
Nビット・データの遅延がほぼ一定で、その上限値Dが既知の場合、値Dを考慮
した適当な遅延素子を挿入した1本のready信号をNビットデータに付加する。
ready信号の0→1遷移が転送先レジスタへの有効データの到着を示す。これを
束データ方式と呼ぶ。
すなわち、非同期式システムでは、共通クロックを使わない代わりに、
Nビットのデータパスを実現するのに、最も楽観的な場合で(N+1)ビット、最
も悲観的な場合には2Nビットのデータ幅が必要になる。実際には、この範囲内
のデータ幅で性能と信頼性のトレードオフを考慮した種々の設計があり得る。
5 非同期式マイクロプロッサの開発事例
クロックを全く用いない完全非同期式マイクロプロセッサの開発プロジェ
クトは現在、東大/東工大における筆者のグループの他に、英国Univ. of
Manchester のAMULET 2e[4]と、米国CalTechのMiniMIPS[5]がある。AMULET2e
は ARM社の32ビットRISCプロセッサの非同期版であり、0.5um、3層メタル、
CMOSプロセスのフルカスタム設計で1 996年10月にチップとして実現されてい
る。電源電圧3.3VでのDhrystone V2.1ベンチマークで40 MIPSの速度性能であ
るが、その消費電力は0.15Wと少ない。一方、MiniMI PSは、MIPS R3000の命令
セットを実現するが一部機能(TLB、外部割り込みなど)を省略した非同期式
簡易型MIPSである。まだ0.6um CMOSプロセスによる設計段階にあり、チップは
できていないが、シミュレーションによれば、3.3V電源、電力消費7Wで28
0MIPSの速度性能を達成している。非同期式システムの高速性を具体的に示す
評価結果と言える。
ここでは、筆者のグループで1997年2月に完成させた非同期式マイクロ
プロセッサTITAC-2[6,7,8]を紹介しよう(脚注1)。
TITAC-2はMIPS-R2000の命令セットを実現した 32ビットのマイクロプロ
セッサである。もちろんクロックはない。しかし、プログラマから非同期式か
どうかは見えない。同期式と同じようにCプログラムが走る。プロセッサ構成
(図2)は、R2000と同様、命令フェッチ(IF)、デコード(ID)、実行(EX)、メ
モリアクセス(ME)、ライトバック(W B)から成る5段パイプライン構造で、40
本の32ビットレジスタ(内、8本はカーネルモードのみ)、8KB命令キャッシュ、
例外処理、外部割り込み、記憶保護機構を備えている。
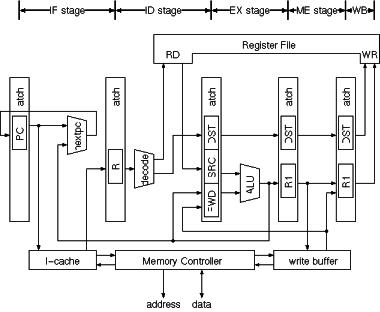
図2:TITAC-2のプロセッサ構成
TITAC-2では、楽観的過ぎも悲観的過ぎもしない、Scalable-
Delay-Insensitive (SD I)モデル[8]と呼ぶ新しい遅延モデルを基に論理設計
を行った。SDIモデルは、回路要素の絶対的な遅延変動には上限値を仮定しな
いが、相対的な変動には限りがある、と仮定するもので、遅延変動に対する信
頼性を確保しつつ、速度性能を向上させることができる。
SDIモデルを適用する設計は以下の指針に従う。
- システム全体を複数の機能ブロックに分割する。
- 各ブロックおよびその接続をQDIモデルに基づいて設計する。
- 使用するプロセス技術およびブロックサイズから相対的遅延変動率の上限値Kを
決定する。
- 各ブロックでK・d1 < d2 が成り立つような局所変換を行う。
SDIモデルを正当化するために、レイアウトには一定の制約が課される。
/TITAC-2ではK=2とした。これを正当化するために、使用した0.5um CMOSプロセ
スに対して、各ブロックは1.93mm x 1.93mm の範囲に収まるようなレイアウト
設計を行った。
TITAC-2チップは、0.5um、3層メタル、3.3V電源CMOSプロセスのスタン
ダード・セル・ライブラリ、及び新規に作成した専用マクロ・セル(C素子、
アービタ、2線式全加算器など)を用いて設計した(脚注2)。図3にそのチッ
プ写真を示す。12.15mm(コアサイズは10.55mm)四方のチップ上に約50万トラ
ンジスタと8.6Kバイトのメモリマクロが集積されている。Dhrystone V2.1ベン
チマークによる実測性能は、室温、電源電圧3.3Vで54.1VAX MIPS、消費電力
2.11Wである。
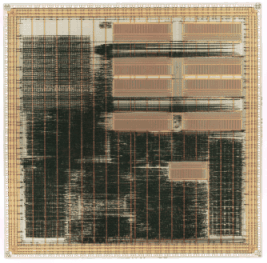
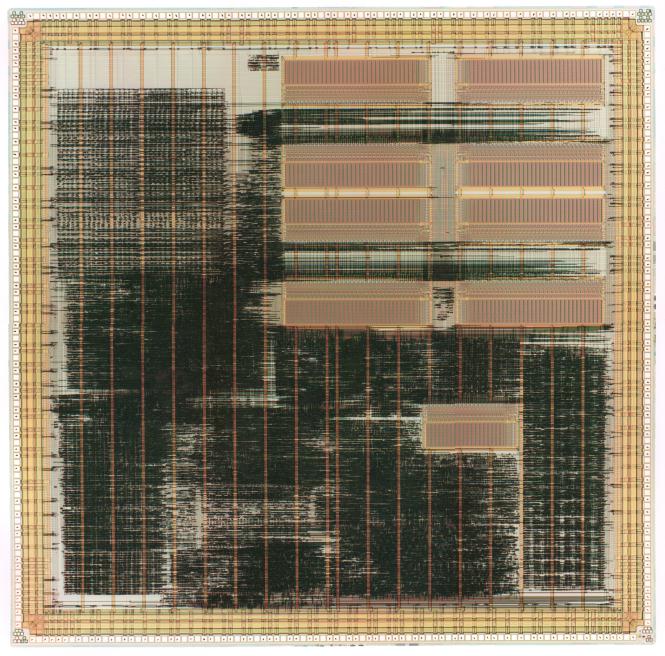
図3:TITAC-2のチップ写真
TITAC-2の特徴はそのDelay-Insensitivityにある。遅延変動を生じさせ
るような環境の変動、例えば、電源電圧やチップ温度の変動に対しても正常に
動作する。但し、当然のことながら、速度性能と消費電力は変化する。図4に
電源電圧を1.5Vから4.0Vまで連続的に変化させた場合のTITAC-2の速度性能
(MIPS)と消費電力(W)の実測値を示す。このように、計算パワーを要求される
場合には、消費電力を上げて高速計算を実行し、そうでない場合は計算性能を
落として消費電力を節減できる。
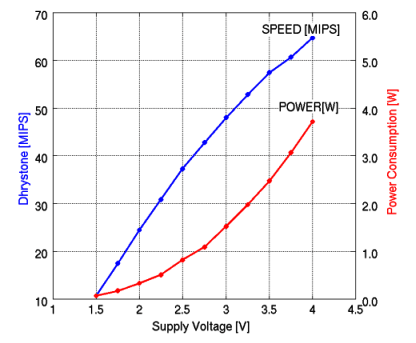
図4:電源電圧に対するTITAC-2の速度性能と消費電力
6 実用化への課題と将来展望
非同期式システムの実現可能性について論じる時期は過ぎた。実用レベ
ルのマイクロプロセッサをクロックなしで実現する設計技術はすでに用意され
ている。今必要なことは、素子性能の向上をシステム性能の向上に直線的に反
映し得る非同期式システムの特性を十分に引き出すアーキテクチャの開発と、
それを実現する非同期式設計技術を現在の成熟した同期式設計と並ぶ選択肢の
一つとして設計者に提供できる設計環境を構築することである。そのためには、
具体的課題として、レジスタ転送レベル記述段階での性能予測手法の開発、
設計支援/検証ツールの開発、テスト手法、過渡性フォールト(ノイズ等)へ
の対策などが挙げられる。
高性能マイクロプロセッサは、ソフトウェアからプロセス技術まであら
ゆるレベルで最先端の技術を総合して実現される。現在の最先端の同期式マイ
クロプロセッサと大学の一研究室で開発されたTITAC-2、AMULET2e、MiniMIPS
などの非同期式マイクロプロセッサとでは設計の環境、資源、スキルなどの条
件がまったく異なるので、簡単には比較できないが、これらの非同期式プロセッ
サの性能は、現在の技術水準でもすでに同期式プロセッサと十分比較し得るレ
ベルに達していると言うことができる。今後、配線遅延が支配要因となる傾向
が進めば、クロックを用いない非同期式システム設計の優位性が一層顕著にな
ると思われる。実際、前述のSIAのロードマップでも、2003年頃に実現が予想
される0.13um技術からは、非同期式チップアーキテクチャが必要になると予測
している[1]。
まだ配線遅延がそれほど支配的とは言えない現在の技術領域でも非同期
式設計が有効だと考えられる応用分野としては、携帯電子機器などの低電力消
費の低減が必要なシステム、環境変動に対する耐性が要求されるシステム、多
数の機能が複合する大規模集積システムなどが挙げられる。
非同期式設計技術は汎用ディジタル技術である。しかし、配線遅延が真
に支配的になると予想される2003年以降でも非同期式が同期式に取って代わる
と考えるのは現実的ではない。最もあり得るシナリオは応用分野に依存した同
期式設計と非同期式設計の棲み分けと融合だろう。すでに、外見はこれまで通
りの同期式プロセッサであるが、内部の命令デコードや、演算部などは高速化
を狙って非同期式設計スタイル取り入れたチップなども出現し始めている。さ
らに微細化と高集積化が進んだ段階での先端VL SIでは、システム全体が非同
期式設計になることは必須となろうが、局所的には高周波クロックを用いた同
期式設計が用いられることも大いにあり得る。いずれにしても、配線遅延が支
配的になるにつれて、VLSI設計スタイルは大きく変わっていくことになろう。
応用分野によって性能、消費電力、信頼性のトレードオフは異なる。そのトレー
ドオフに応じた同期/非同期融合アーキテクチャの開発が今後の課題である。
謝辞:本研究の一部は科研費補助金基盤研究(B)09480049、及び(株)
半導体理工学研究センターとの共同研究によるものである。
参考文献
- The National Technology Roadmap for Semiconductors, 1997 Edition,
SEMATECH, Inc (Dec.1997)
- 南谷崇「非同期式プロセッサ - 超高速プロセッサを目指して」情報処理、Vol.34
, No.1, pp.72-80 (Jan. 1993).
- Nanya, T.:Challenges to Dependable Asynchronous Processor Design, in
Logic Synthesis and Optimization, Kluwer Academic Publishers(Nov. 1992).
- S.B.Furber, J.D.Garside, S.Temple, J.Liu, P.Day, N.C.Paver :"AMULET2e:
An Asynchronous Embedded controller", Proc. of ASYNC'97, pp.290-299 (April
1997).
- A.J.Martin, A.Lines, R.Manohar, M.Nystrom, P.Penzes, R.Southworth,
U.Cummings, T.K.Lee :"The Design of an Asynchronous MIPS R3000
Microprocessor", Proc.ARVLSI'97 (Sep. 1997).
- 高村、桑子、南谷:”非同期式プロセッサTITAC-IIの論理設計における高速化手
法”、電子情報通信学会論文誌, Vol.J80-D-I, No.3, pp.pp.189-196 (March 1997)
- T.Nanya, A. Takamura, M. Kuwako, M. Imai, T. Fujii, M. Ozawa, I.
Fukasaku, Y. Ueno, F.Okamoto, H. Fujimoto, O. Fujita, M. Yamashina, M.
Fukuma :"TITAC-2: A 32-bit Scalable-Delay-Insensitive Microprocessor",
HOT Chips IX, Stanford, pp.19-32 (Aug. 1997)
- A. Takamura, M. Kuwako, M. Imai, T. Fujii, M. Ozawa, I. Fukasaku, Y.
Ueno and T. Nanya:"TITAC-2: A 32-bit Asynchronous Microprocessor based on
Scalable-Delay-Insensitive Model" Proc.ICCD'97 (Oct. 1997)
- 脚注1:
-
TITAC-2の完成は過去数年に渡る東工大/東大・南谷研究室
メンバーの努力の結晶であるが、特に上野洋一郎、桑子雅史、高村明裕、
今井雅、藤井太郎、小沢基一、深作泉、石川誠、Rafael Morizawaの諸君
の奮闘に依るところが大きい。
- 脚注2:
-
チップ実現に関してNEC(株)の高田正日出、山田八郎、福
間雅夫、山品正勝、藤田修、藤本裕樹、岡本冬樹の諸氏に助言やご協力を
いただいた。
TITAC2のページへ戻る